
Як змусити Search і Discover показувати саме твоє ідеальне зображення
Що змінює Google Ads API Developer Assistant v2.0?

Як стилістичні особливості впливають на взаємодію користувачів

12 хвилини
Зображення більше не сприймаються пошуковими та AI-системами як другорядний елемент контенту. Сьогодні вони аналізуються так само, як і мова: через OCR, візуальний контекст та якість на рівні пікселів. Саме ці фактори визначають, як штучний інтелект інтерпретує контент і чи буде він використаний у відповідях, рекомендаціях або генеративному пошуку.
Протягом останнього десятиліття image SEO зводилося переважно до технічної гігієни:
Ці практики й досі залишаються базовими для здорового сайту. Проте поява великих мультимодальних моделей — таких як ChatGPT або Gemini — створила нові можливості й водночас нові виклики.
Мультимодальний пошук об’єднує різні типи контенту в спільному векторному просторі.
Фактично ми більше не оптимізуємося лише для користувача — ми оптимізуємося для «машинного погляду».
Генеративний пошук робить більшість контенту машинозчитуваним: медіа розбиваються на смислові блоки, а текст із зображень витягується за допомогою оптичного розпізнавання символів (OCR).
Зображення мають бути читабельними для «ока» машини.
Якщо AI не може коректно зчитати текст на упаковці продукту через низький контраст або починає «домислювати» деталі через погану роздільну здатність — це вже серйозна SEO-проблема, а не просто питання дизайну.
Ця стаття розбирає, як працює машинний погляд, і зміщує фокус із швидкості завантаження на машинну читабельність.
Перш ніж оптимізувати контент для розуміння AI, необхідно врахувати базовий фільтр — продуктивність.
Зображення є двосічним мечем.
Вони підвищують залученість, але водночас часто стають основною причиною:
Сьогодні стандарт «достатньо добре» вже виходить за межі просто WebP.
Для великих мовних моделей (LLM) зображення, аудіо та відео — це джерела структурованих даних.
Вони використовують процес, який називається візуальною токенізацією: зображення розбивається на сітку патчів (візуальних токенів), а сирі пікселі перетворюються на послідовність векторів.
Завдяки уніфікованій моделі AI може обробляти фразу на кшталт
«зображення [image token] на столі»
як єдине цілісне речення.
Ключову роль у цьому процесі відіграє OCR — саме він витягує текст безпосередньо з візуального контенту.
І тут якість стає фактором ранжування.
Якщо зображення надмірно стиснуте й містить артефакти втрати якості, візуальні токени стають «шумними». Низька роздільна здатність призводить до того, що модель неправильно інтерпретує ці токени.
Результат — галюцинації: AI впевнено описує об’єкти або текст, яких насправді не існує, лише тому, що «візуальні слова» були нечіткими.
Для великих мовних моделей alt-текст отримує нову функцію — ґраундинг.
Він виступає семантичним орієнтиром, який змушує модель зняти неоднозначність візуальних токенів і підтвердити власну інтерпретацію зображення.
Як зазначають Zhang, Zhu та Tambe:
«Вставляючи текстові токени поблизу релевантних візуальних патчів, ми створюємо семантичні сигнальні маркери, які розкривають реальні показники міжмодальної уваги та спрямовують модель».
Практична порада:
Описуючи фізичні характеристики зображення — освітлення, композицію, розташування елементів і текст на об’єкті — ви фактично надаєте високоякісні навчальні дані. Вони допомагають «машинному оку» корелювати візуальні та текстові токени.
Пошукові агенти на кшталт Google Lens або Gemini активно використовують OCR для зчитування:
На основі цього вони здатні відповідати на складні користувацькі запити.
У результаті image SEO виходить за межі сайту й поширюється на фізичну упаковку.
Чинні регуляторні вимоги — FDA 21 CFR 101.2 та EU 1169/2011 — дозволяють мінімальні розміри шрифту 4,5–6 pt або 0,9 мм для компактної упаковки.
«У випадку упаковки або контейнерів, найбільша поверхня яких має площу менше ніж 80 см², висота x-елемента шрифту має бути не меншою за 0,9 мм».
Це задовольняє людське око — але не машинний погляд.
Мінімальна піксельна висота символів для стабільного OCR має становити щонайменше 30 пікселів.
Контраст також критичний: різниця повинна досягати 40 градацій сірого.
Окрему небезпеку становлять декоративні та стилізовані шрифти. OCR-системи легко плутають:
Додаткові проблеми створюють глянцеві поверхні. Вони відбивають світло й утворюють бліки, що частково або повністю перекривають текст.
Упаковку слід розглядати як функцію машинної читабельності, а не лише елемент брендингу.
Якщо AI не може розібрати фото упаковки через відблиски або рукописний шрифт, він може вигадати дані або, що ще гірше, взагалі не включити продукт у результати.
Оригінальність часто сприймається як суб’єктивна творча характеристика. Проте в контексті AI її можна вимірювати як конкретний сигнал.
Оригінальні зображення працюють як канонічний маркер.
Google Cloud Vision API, зокрема функція WebDetection, повертає списки:
fullMatchingImages — точні дублікати зображень у мережі;pagesWithMatchingImages — сторінки, де вони зустрічаються.Якщо ваша URL-адреса має найранішу дату індексації для унікального набору візуальних токенів (наприклад, нестандартного ракурсу продукту), Google зараховує ваш сайт як першоджерело цього візуального сигналу.
Це напряму підсилює показник experience, який дедалі більше впливає на видимість у пошуку нового покоління.
Штучний інтелект ідентифікує кожен об’єкт на зображенні та аналізує зв’язки між ними, щоб зробити висновки про бренд, ціновий сегмент і цільову аудиторію.
Саме тому сусідство продуктів у кадрі (product adjacency) стає фактором ранжування.
Щоб оцінити цей сигнал, необхідно провести аудит візуальних сутностей.
Для тестування можна використовувати інструменти на кшталт Google Vision API.
Якщо ж ідеться про системний аудит усієї медіабібліотеки, потрібно отримати сирий JSON-вивід, використовуючи функцію OBJECT_LOCALIZATION.
API повертає мітки об’єктів, наприклад:
“watch”, “plastic bag”, “disposable cup”.
Google наводить такий приклад, де API ідентифікує об’єкти на зображенні та повертає такі дані:
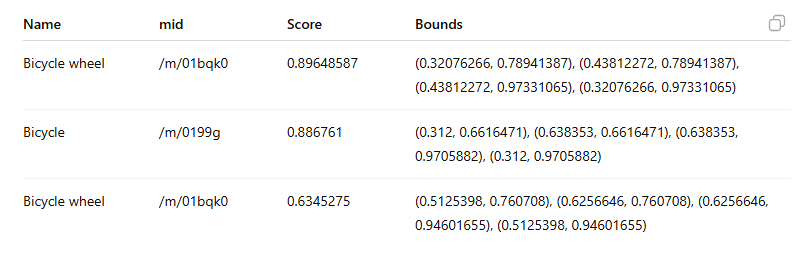
Важливо: поле mid містить машинно згенерований ідентифікатор (MID), який відповідає сутності в Google Knowledge Graph.
API не знає, чи є цей візуальний контекст «хорошим» або «поганим».
Це знаєте ви.
Тому ключове завдання — перевірити, чи візуальні сусіди продукту розповідають ту саму історію, що й його ціна.
Фотографуючи синій шкіряний ремінець для годинника поруч зі старовинним латунним компасом і поверхнею з теплою текстурою дерева, бренд Lord Leathercraft формує чіткий семантичний сигнал: спадщина та дослідження.
Співприсутність аналогових механізмів, зістареного металу та тактильної замші формує образ людини, яка цінує позачасову пригоду та аристократичну вишуканість старого світу.
Але варто сфотографувати той самий годинник поруч із неоновим енергетиком і пластиковим цифровим секундоміром — і наратив змінюється через дисонанс.
Візуальний контекст починає сигналізувати масмаркетну утилітарність, знецінюючи сприйняття сутності продукту.
Окрім об’єктів, ці моделі дедалі краще зчитують емоційний стан.
API, зокрема Google Cloud Vision, здатні кількісно оцінювати емоційні атрибути, присвоюючи ймовірнісні оцінки таким емоціям, як joy (радість), sorrow (смуток) і surprise (здивування), які визначаються за людськими обличчями.
Це створює новий вектор оптимізації — емоційне узгодження.
Якщо ви продаєте веселі літні образи, але моделі на фото виглядають похмурими або нейтральними (поширений прийом у high-fashion-зйомках), AI може знизити пріоритет такого зображення для відповідного запиту. Причина — конфлікт між візуальним настроєм і пошуковим наміром.
Для швидкої перевірки без написання коду можна скористатися живою drag-and-drop демоверсією Google Cloud Vision, яка дозволяє переглянути чотири базові емоції:
Для позитивних запитів, наприклад «щаслива сімейна вечеря», атрибут joy має визначатися як VERY_LIKELY.
Якщо ж значення — POSSIBLE або UNLIKELY, сигнал надто слабкий, щоб машина впевнено проіндексувала зображення як «щасливе».
Для системного аналізу:
faceAnnotations, використовуючи запит із параметром FACE_DETECTION.likelihood.API повертає ці значення у вигляді фіксованих категорій (enum).
Приклад безпосередньо з офіційної документації:
API оцінює емоції за фіксованою шкалою.
Мета оптимізації — перевести ключові зображення з рівня POSSIBLE на LIKELY або VERY_LIKELY для цільової емоції.
UNKNOWN — відсутність даних.VERY_UNLIKELY — сильний негативний сигнал.UNLIKELY.POSSIBLE — нейтрально або неоднозначно.LIKELY.VERY_LIKELY — сильний позитивний сигнал (ціль).Оптимізація емоційного резонансу неможлива, якщо машина ледь розпізнає обличчя.
Якщо detectionConfidence нижче 0,60, AI має труднощі з ідентифікацією обличчя. У такому випадку будь-які емоційні показники є статистично ненадійним шумом.
Рекомендовані пороги:
Хоча документація Google не надає чітких рекомендацій щодо цих порогів, а Microsoft обмежує доступ до Azure AI Face, в документації Amazon Rekognition зазначено:
«Нижчий поріг (наприклад, 80 %) може бути достатнім для ідентифікації членів родини на фотографіях».
Візуальні активи слід опрацьовувати з тією ж редакторською строгістю та стратегічним наміром, що й основний контент. Семантичний розрив між зображенням і текстом зникає.
Зображення обробляються як частина мовної послідовності. Якість, чіткість і семантична точність самих пікселів тепер мають таке ж значення, як і ключові слова на сторінці.
Читайте статтю англійською мовою.
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
Послуги digital маркетингу для середнього та великого бізнесу. Digital стратегія. Performance маркетинг. Веб-аналітика.
Ми зосереджені на створенні креативних стратегій, бренд-комунікацій, нестандартних механік і діджиталу.
School of Digital Advertising UAMASTER – навчаємо новим цифровим дисциплінам. Переходь на сайт і знайомся з програмою курсу "Digital маркетинг"
Все, що маркетологу необхідно знати про веб-аналітику у 2023 році
Професійне налаштування Google Analytics 4 Коректний збір даних в GA4. Зрозуміла та корисна звітність.
Для пошуку введіть назву або слово


